I am working on a modified NSGA-2 to converge on the Pareto frontier in fewer generations than the standard version. My idea is to use clustering to determine the region of independent variable space that is the most promising of those tried in a given generation. By knowing the best spatial region, it should be possible to generate solutions in that region to gain more information than could be gathered breeding initial poor solutions.
My first attempt took a rather simple approach. I made it so that the fast non-dominated sort (FNDS) chose some percentage of the parents for the next generation, and the rest were generated within the most promising space as determined by the above sort. This space was determined by clustering solutions by reducing the standard deviations of the independent variables down to a minimum cluster size of 20, then selecting the cluster that had the lowest mean frontier rank.
This attempt seems to have some promise. Here is a graph showing the baseline performance of the standard NSGA-2 on the Fonseca study:
This is a graph of the two objective scores for all members of the first-ranked frontier for each generation. By generation 20 (far right), NSGA-2 has found a very nice distribution of answers across the Pareto frontier. The first generation that looks close enough to me is generation 14. Note how the first few generations are rather noisy; it isn't until generation 8 that the solutions starts to mostly lie on the Pareto frontier.
As a counterpoint, here is a like graph of my modified NSGA-2. For this run, FNDS selects 80% of the parents, and the remaining 20% are generated from the best cluster:
First, note how the generations converge toward the frontier more rapidly than the baseline. Fewer of the solutions for the initial generations are far away from the Pareto frontier, and by generation 6, the Pareto frontier is outlined almost as strongly as it is in generation 8 from the baseline.
There seem to be diminishing returns from this approach, however. After the baseline NSGA-2 has "discovered" the Pareto frontier, it smoothly converges onto it and distributes solutions across it rather nicely. My modified NSGA-2 seems to be injecting noise that keeps it from converging smoothly across the solution space. This is probably because NSGA-2 is designed to distribute solutions across the Frontier, whereas my current clustering approach searches only one part of it. Furthermore, no adjustments are currently made to account for the algorithm getting closer to the answer, so good solutions are getting replaced by guesses made by the clusterer.
For the next step, I will explore ways to make the clusterer explore all the promising spaces as opposed to just the best one, and also to dynamically adjust the ratio of FSDN-selected parents to cluster-selected parents based upon the proximity to the Pareto frontier.
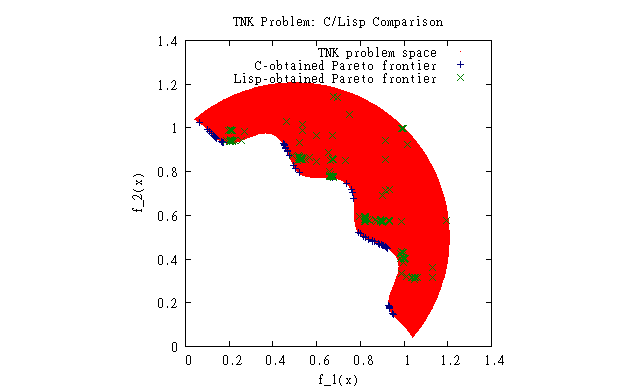 This was the first comparison between the C version and my version. I would have made a new graph, but I somehow lost the C frontier data. I saw that something was very wrong, so I have spent a lot of time trying to fix it. This is as close as I've gotten thus far:
This was the first comparison between the C version and my version. I would have made a new graph, but I somehow lost the C frontier data. I saw that something was very wrong, so I have spent a lot of time trying to fix it. This is as close as I've gotten thus far:



