Not a whole lot yet because of mid-terms last week, plus lost about 2 days when I couldn't get Texmaker installed in Ubuntu properly.
Blarg
Tuesday, February 28, 2012
Idea Supervised vs Unsupervised Win Tie Loss and more
These are Win Tie Loss statistics based on Mann-Whitney for IdeaSupervised and Unsupervised for 20 datasets and below are some initial rankings for Cocomo81s and Kemerer comparing all methods. For the rankings im not sure if they are correct, maybe you could have a look and give me some feedback.

http://dl.dropbox.com/u/7054701/Cocomo81s%20ranking.jpg
http://dl.dropbox.com/u/7054701/Kemerer%20ranking.jpg
Monday, February 27, 2012
Taking Size Out of Data Sets
For the time being I have cocomo, nasa, sdr and desharnais data sets.
The comparison of with-size vs. without-size results for the top13 solo-methods are here.
The comparison of with-size vs. without-size results for the top13 solo-methods are here.
Week in Summary
The 400 Project
> A "master list" of "rules" of game design
Much literature on game design and methodologies. They say to "tune" the game after you design/develop it. But nothing found on methodologies for "tuning".
> Some games involve beta process. Takes in lots of feedback, only one chance to revise.
> Some games have testers who report feedback quickly. Many chances to revise.
> > Testing process draws out and takes time: lots of money.
> Want something that does not involve testers
Working on Qualifier Paper & Presentation
> Section I: History of Gaming and other background information
> > Pre-computing era (Ancient Civilization - 1950)
> > Early Computing Era (1950 - 1980)
> > Computing Era (1980-2000)
> > Golden Age of Gaming (2000 - present)
> Section II: Overview of Games Studies, and Role of Engineering in Games Studies
> Section III: My own research (and what kind of Games Studies it is)
Revise an unsuccessful game into something successful
> Tons of games which are unsuccessful
> Study these games and analyze them
> > What went wrong?
> > Suggest revisions that could have made them successful instead
> I'm currently studying an old game called Deadly Towers
> Coding up a game could take months
> > Working on existing game code involves coding in assembly
Sunday, February 26, 2012
LISP code for differential evolution
For more on
Global Optimisation Algorithms, see
- A general overview;
- Some notes on downhill simplex optimisation.
Wednesday, February 22, 2012
learning for imbalanced data
Learning from Imbalanced Data
Haibo He, Member, IEEE, and Edwardo A. Garcia
Abstract—With the continuous expansion of data availability in many large-scale, complex, and networked systems, such as surveillance, security, Internet, and finance, it becomes critical to advance the fundamental understanding of knowledge discovery and analysis from raw data to support decision-making processes. Although existing knowledge discovery and data engineering techniques have shown great success in many real-world applications, the problem of learning from imbalanced data (the imbalanced learning problem) is a relatively new challenge that has attracted growing attention from both academia and industry.
The imbalanced learning problem is concerned with the performance of learning algorithms in the presence of underrepresented data and severe class distribution skews. Due to the inherent complex characteristics of imbalanced data sets, learning from such data requires new understandings, principles, algorithms, and tools to transform vast amounts of raw data efficiently into information and knowledge representation.
In this paper, we provide a comprehensive review of the development of research in learning from imbalanced data. Our focus is to provide a critical review of the nature of the problem, the state-of-the-art technologies, and the current assessment metrics used to evaluate learning performance under the imbalanced learning scenario.
Furthermore, in order to stimulate future research in this field, we also highlight the major opportunities and challenges, as well as potential important research directions for learning from imbalanced data.
Index Terms—Imbalanced learning, classification, sampling methods, cost-sensitive learning, kernel-based learning, active learning, assessment metrics.
Tuesday, February 21, 2012
Paper Final
Deadline for ICSE-GAS'12 extended to Feb 24.
New Stuff:
- Subdividing Board Gaming data with Rules (Figure 7.)
^ Important when data doesnt match expectations.
Next:
- More Data; Shooter Types and RTS Games
- Another MMORPG and Board Game, to collaborate existing data
- Learn what people think Core and Casual mean (refine data collection)
Monday, February 20, 2012
Saturday, February 18, 2012
Differential Evolution: a Better Optimizer?
Differential Evolution
Differential Evolution: A Survey of the State-of-the-Art Swagatam Das, Ponnuthurai Nagaratnam Suganthan, IEEE TRANSACTIONS ON EVOLUTIONARY COMPUTATION, VOL. 15, NO. 1, FEBRUARY 2011- Compared to most other EAs, DE is much more simple and straightforward to implement. Main body of the algorithm takes four to five lines to code in any programming language. Simplicity to code is important for practitioners from other fields, since they may not be experts in programming and are looking for an algorithm that can be simply implemented and tuned to solve their domain-specific problems. Note that although PSO (particle swarm optimization) is also very easy to code, the performance of DE and its variants is largely better than the PSO variants over a wide variety of problems as has been indicated in many studies.
- As indicated by recent studies, despite its simplicity, DE exhibits much better performance in comparison with several others like G3 with PCX, MA-S2, ALEP, CPSO-H, and so on of current interest on a wide variety of problems including uni-modal, multimodal, separable, non-separable and so on. Although some very strong EAs like the restart CMA-ES was able to beat DE at CEC 2005 competition, on non-separable objective functions, the gross performance of DE in terms of accuracy, convergence speed, and robustness still makes it attractive for applications to various real-world optimization problems, where finding an approximate solution in reasonable amount of computational time is much weighted.
- The number of control parameters in DE is very few (Cr, F, and NP in classical DE). The effects of these parameters on the performance of the algorithm are well- studied. As will be discussed in the next section, simple adaptation rules for F and Cr have been devised to improve the performance of the algorithm to a large ex- tent without imposing any serious computational burden.
- The space complexity of DE is low as compared to some of the most competitive real parameter optimizers like CMA-ES. This feature helps in extending DE for handling large scale and expensive optimization problems. Although CMA-ES remains very competitive over problems up to 100 variables, it is difficult to extend it to higher dimensional problems due to its storage, update, and inversion operations over square matrices with size the same as the number of variables.
Single Objective Differential Evolution
R. Storn and K. V. Price, "Differential evolution: A simple and efficient adaptive scheme for global optimization over continuous spaces," ICSI, USA, Tech. Rep. TR-95-012, 1995. Available: http://icsi.berkeley.edu/~storn/litera.htmlGlobals
- F : combiation factor (try F=0.3)
- Cr : cross over rate (try Cr=0.5)
- NP: number of items in population (try NP=100)
de
function de(NP, F)
Generate NP random solutions
for each item P
value[P] = score(P)
Stop = false
while not Stop
For each item P
C = candidate(P)
value[C] = score(C)
if (better(value[C], value[P]))
replace P with C
print BestScore,Best
score
function score(X)
tmp = objectiveFunction(X) # domain specific
if (tmp > Best)
BestScore = tmp
Best = X
if (BestScore >= GoodEnough)
Stop = true
Count++
if (Count > TooMuch)
Stop = true
return tmp
candidate
function candidate(original)
pick three other items at random x,y,z
candidate = ()
for each attribute A
new = x[A]
if numeric(A)
new = x[A] + f*([y[A] - z[A]])
else
if (rand() < f) new = (rand() < 0.5) ? y[A] : z[A])
candidate[A] = new
for each attribute A
candidate[A] = (rand() < Cr) ? original[A] : candiate[A]
k = a random attribute
candidate[A] = original[k] #must use at least 1 parent attribute
return candidate
Variants
Varitions on a Theme
Storn and Price suggested a total of ten different working strategies for DE and some guidelines in applying these strategies to any given problem.K. Price, R. Storn, and J. Lampinen, "Differential Evolution—A Practical Approach to Global Optimization" Berlin, Germany: Springer, 2005.
_R. Storn and K. Price, "Differential evolution: A simple and efficient heuristic for global optimization over continuous spaces" J. Global Optimization, vol. 11, no. 4, pp. 341-359, 1997. _
None work best in all circumstances. Suck it and see!
Opposition-based DE
When building the candidate, select the opposite value of each numeric range- For an attribute ranging 2..12
- The opposite of 4 is 10
Multiple objective DE
Tea Robic and Bogdan Flipic, 2005.If first standard DE, the candidate is compared to its parent (so the "orginal" is the parent) and there is only a single objective function.
In the next two variant, we allow multiple goals and we apply domination
Domination : y1 dominates y2 if
for all objective o, o(y1) <= o(y2)
and there exists one objective o, o(y1) < o(y2)
- If child dominates, replace original
- If neither doiminates, keep original and add child
The third variant, DEMO/closest/obj, works in the same way as standard, the "original" is the closest item in the objective space.
Tuesday, February 14, 2012
Wilcoxon ranked-sum or Mann-Whitney U test in Bash! on Idea
Idea versus 90 solo methods using the statistical Matt-Whitney U test.

Monday, February 13, 2012
How would data cluster 90 solo-methods
This ad-hoc procedure uses 2 statistical test
The results of the above procedure are incorporated into the jiggle paper on p16-17.
Concise summary of results:
- Wilcoxon Rank Sum Test: To compare 2 arrays of MRE's
- Kruskal-Wallis: To compare n arrays of MRE's
- Sort the solo-methods by their MdMRE's
- Start with j'th group (initially j=1) and place the i'th solo-method into this group
- Compare MRE's of i'th and i+1'th solo-method w.r.t. Wilcoxon
- Compare MRE's of all solo-methods in j'th group and MRE of i+1'th w.r.t. Kruskal-Wallis
- If step3 and step4 both agree that i+1'th method is statistically the same, then place it into j'th group
- Else (if one of step3 or step4 says i+1'th is statistically different), then increment j by 1, i.e. form a new group.
- i = i+1;
- Go to step2
The results of the above procedure are incorporated into the jiggle paper on p16-17.
Concise summary of results:
- Some dataset are awfully flat without any ability to form a second group: telecom and kemerer.
- The datasets that show a good distribution of the solo-methods to their groups is around half the data sets: cocomo81e, nasa93_center_5, desharnais, nasa_93_center_2, sdr, finnish, cocomo81, miyazaki94, nasa93
- The occurrence of the top13 solo-methods within these groups still proves our point, i.e. they are mostly on the top group. However, for certain datasets (desharnaisL3, cocomo81o) the generality does not hold, and the top13 solo-methods occur in lower-performance groups.
- The above result shows that, the generality that we have found from the aggregate of 7 error measures and 20 data sets via win-tie-loss values, still holds when we look at the specifics (just using the MRE's w.r.t. another procedure based on multiple statistical tests). However, we still cannot say that there will be no exceptions due to data sets like desharnaisL3 and cocomo81o.
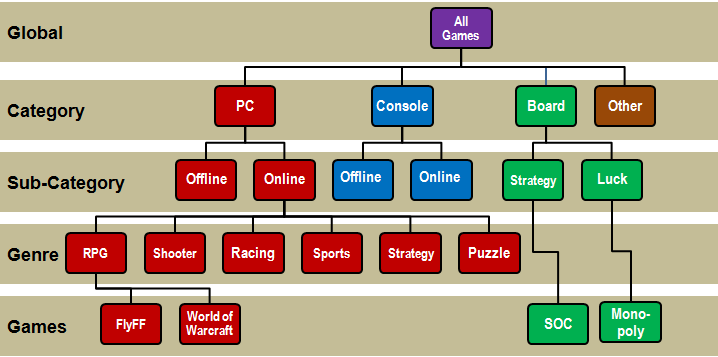
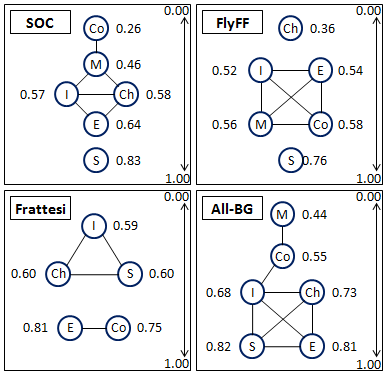
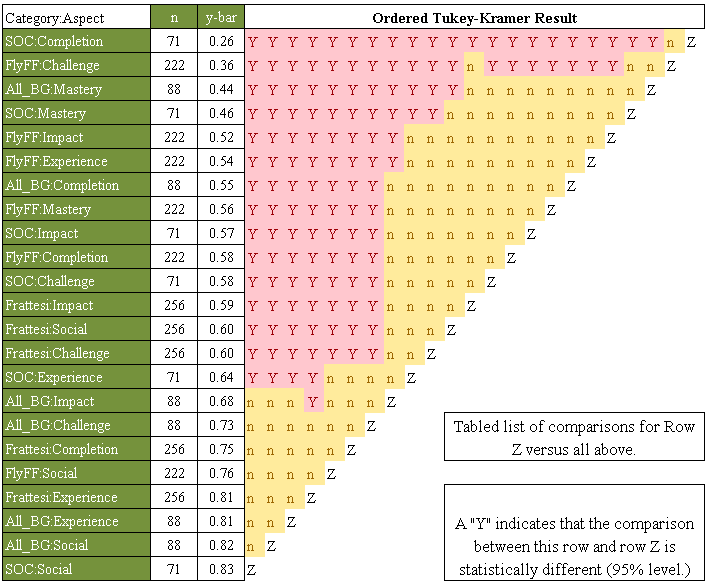
Aspects of Replayability Paper
Paper Week 4: almost final. Feb 17th submission deadline (Zurich timezone) [ICSE-GAS'12]
New "Game Class diagram":
- Only sensible to compare game-instances with siblings or parents
"JDK Diagrams" = Just Don't Kare (named after Joseph D...err... Henry Krall):
- Used to analyze game data
- Offers tukey-kramer analysis, where edges represent statistical indistinguishable-ility
- We only "kare" about nodes which aren't connected, in practice.
Sunday, February 12, 2012
Spectral learning
Spectral learners are those that deal with the eigenvectors of a space.
Why spectra? Well, according to Wikipedia:

So we are doing spectral learning which means that, in theory, our ASE'11 paper could be greatly improved a learner that uses the eigenvectors directly rather than the FASTMAP approximation.
For yet more on spectral learning, see (in stuff/doc):
Note the last paper. The clustering method andrew and me "invented" in 2010 actually dates back to 1998. sigh. our only innovation was to (1) approximate the eigenvectors with fastmap and (2) try it on SE data and (3) compare it to results from the global spalce.
Why spectra? Well, according to Wikipedia:
- A spectrum (plural spectra or spectrums[1]) is a condition that is not limited to a specific set of values but can vary infinitely within a continuum. The word saw its first scientific use within the field of optics to describe the rainbow of colors in visible light when separated using a prism; it has since been applied by analogy to many fields other than optics. Thus, one might talk about the spectrum of political opinion, or the spectrum of activity of a drug, or the autism spectrum. In these uses, values within a spectrum may not be associated with precisely quantifiable numbers or definitions. Such uses imply a broad range of conditions or behaviors grouped together and studied under a single title for ease of discussion.
- In most modern usages of spectrum there is a unifying theme between extremes at either end. Some older usages of the word did not have a unifying theme, but they led to modern ones through a sequence of events set out below. Modern usages in mathematics did evolve from a unifying theme, but this may be difficult to recognize.
- In mathematics, the spectrum of a (finite-dimensional) matrix is the set of its eigenvalues. This notion can be extended to the spectrum of an operator in the infinite-dimensional case.
This idea of the spectrum actually sums up years of my own thinking. SE theory has treated a software project as "one thing" when actually it is a spectrum of things- and we can best study it if we study the data's spectrum).
So, there is a relatively recent newer class of learners that base their reasoning on the eigenvectors. If you don't know what is an eigenvector, they are the invariant properties of a matrix. Its direction, if you will. For example, if we take the eigenvectors of a co-variance matrix, we get the major directions of that data
For more, see http://www.slideshare.net/guest9006ab/eigenvalues-in-a-nutshell or http://www.cs.otago.ac.nz/cosc453/student_tutorials/principal_components.pdf (the first is better for visuals, the second is better for explanatory text).
Now I raise this snince Andrew's learner and the IDEA that Raymond is working with spectra since these are based on Fastmap and...
First published in 1995, FastMap algorithm has been significantly elaborated since then. Wang et al.’s MetricMap algo- rithm tries to replace the iterative projections of Figure 2 with a single multi-profject method [43]. See also the theoretical analysis of Platt that shows that FastMap and MetricMap are really instances of a broader class of what is known as Nystrom algorithms [44]; i.e. they are based on the Nystrom approximation of the eigenvectors of a large matrix.
[43] T. L. Wang, X. Wang, D. Shasha, and K. Zhang, “Metricmap: An embedding technique for processing distance-based queries in metric spaces,” IEEE Transactions on Systems, Man, and Cybernetics, Part B, vol. 35, p. 2005.
[44] J. C. Platt, “Fastmap, metricmap, and landmark mds are all nystro ̈m algorithms,” in In Proceedings of 10th International Workshop on Artificial Intelligence and Statistics, 2005, pp. 261–268.
For yet more on spectral learning, see (in stuff/doc):
- 08spectralLearning.pdf
- 03spectralLearning.pdf
- 05spectralDivisvePartitioning.pdf
- 02_part2_principalDirectionDivisvePartitioning.pdf
- 08farthestCentroidsDivisiveClustering.pdf
- 98principalDirectionDivisvePartitioning.pdf
Note the last paper. The clustering method andrew and me "invented" in 2010 actually dates back to 1998. sigh. our only innovation was to (1) approximate the eigenvectors with fastmap and (2) try it on SE data and (3) compare it to results from the global spalce.

{kind=link}
{kind=link}
Starting with "why"

Simon Sinek: “people don’t buy what you do, they buy why you do it.”
e.g. Martin Luther King did not say "I have a plan", instead, he said "I have a dream."
e.g. Apple works this way:
e.g. Apple works this way:
- WHY: We exist to think different, to make things better ...
- HOW: ... we are a design company who happens to ...
- WHAT: ... make easy to use computers.
If we find a "why" that other people want, you we can sell our papers, sell our software, sell our careers.
e.g. I have a journal paper with ten times the usual number of citations in that particular journal. That paper had
e.g. I have a journal paper with ten times the usual number of citations in that particular journal. That paper had
- WHY: more people can work together to increase the rigor of our discipline by ...
- HOW: ... using machine learning and a clearer reporting of the results ...
- WHAT: ... using data sets from NASA and algorithms from WEKA, both of which are on-line and you can get running today.
Tuesday, February 7, 2012
This week
We are done with the active learning paper (waiting for reviews). Submission this week.
Read all the available information on Grammatech and placed them here.
Read all the available information on Grammatech and placed them here.
- Question: I have only 3 reports... More stuff to read for me to catch up?
- Question: How to manage the citations? Mendeley is pretty easy to use (see the draft).
Monday, February 6, 2012
{kind=link}
Subscribe to:
Posts (Atom)