Tuesday, March 20, 2012
LOC-compensation Paper
The latest version of the paper is here. There is still a lot of polishing to do, but the general frame of the paper tells our story (particularly the abstract).
Monday, March 19, 2012
IDEA PROMISE12
ABSTRACT
Background: Most software effort estimation research focuses on methods that produce the most accurate models but very little focuses on methods of mapping those models to business needs.
Aim: Rather than focusing only on algorithm mining, placing the main spotlight on the learner, here we focus on techniques to apply the model in the real world as well. We propose an algorithm called IDEA which creates a dendrogram that can be used to base project parameters decisions to optimize results.
Method: IDEA is compared to 90 solo-methods on 20 datasets using median MRE values. We also show worked examples of how to apply IDEA’s results to project parameter decisions.
Results: By applying IDEA to software effort estimation datasets we generate dendrograms used to make project parameter choices. IDEA does better than most methods 15% of the time, it does just as good as any other method 30% of the time, 35% of the time it does as good as half and 20% of the time it’s in the middle.
Conclusion: IDEA is a linear-time algorithm which can be used effectively to facilitate project decisions and is comparable or better than at least 90 solo-methods tested on 20 effort datasets found in the literature.
Game Surveys
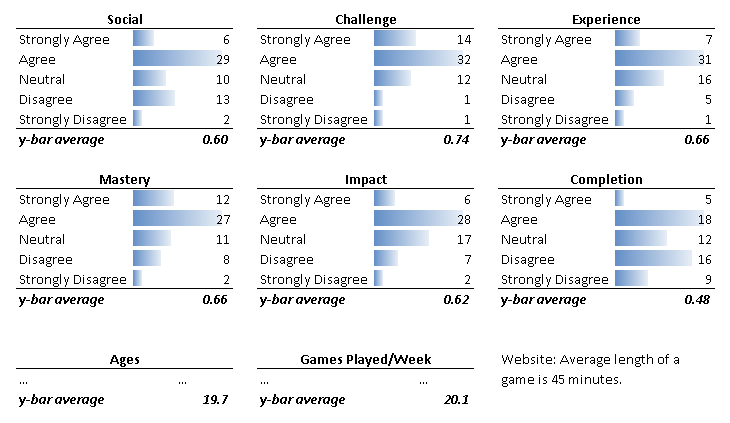
Survey for "League of Legends" now open.
- 69 Results so far, still early in the week.
Survey is here:
http://www.esurveyspro.com/Survey.aspx?id=5cd0fddb-2e5c-451f-bd1e-4dd49e571a1d
Tuesday, March 13, 2012

{kind=link}
Idea updates
Modified code to include all Datasets for median plot
http://unbox.org/stuff/var/ray/Plotting/Quartiles/medians.pdfIQR charts for 6 datasets
Dendrograms for all datasets, questions
Monday, March 12, 2012
Grammatech Report
Saturday, March 10, 2012
very fast multiple objective optimization?
This paper
- Ostrouchov, G.; Samatova, N.F.; , "On FastMap and the convex hull of multivariate data: toward fast and robust dimension reduction," Pattern Analysis and Machine Intelligence, IEEE Transactions on , vol.27, no.8, pp.1340-1343, Aug. 2005 doi: 10.1109/TPAMI.2005.164 URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1453521&isnumber=31215
- Says that "FastMap is a dimension reduction technique that operates on distances between objects. Although only distances are used, implicitly the technique assumes that the objects are points in a p-dimensional Euclidean space. It selects a sequence of k ≤ p orthogonal axes defined by distant pairs of points (called pivots) and computes the projection of the points onto the orthogonal axes. We show that FastMap uses only the outer envelope of a data set. Pivots are taken from the faces, usually vertices, of the convex hull of the datapoints in the original implicit Euclidean space."
That is, the pivots found by Fastmap map out vertexes in the the convex hull (the minimum polygon that contain all points)
Now they don't go the next step (which I think is obvious). To do multi-objective optimization,

- generate candidates
- apply recursive divisive clustering with fastmap, keeping track of all the pviots found along the way
- apply pareto domination to just the pivots, deleting the dominated ones
- use the survivors as parents for the GAs or DEs
- loop
Also, this could be a cache for on-line multi-objective optimization.
- find 1000 examples, recursively cluster them with fastmap.
- Set "important" to be the pivots found in this process
- 1000 times
- find one more example.
- if it falls between pivots, ignore it. else, add it to "important"
- Recursively cluster the important points.
- Set a new "important" set to be the pivots found in this process
- Goto step 2
- Apply the above on-line learner
- When pivots are created, ask an oracle for the value of those pivots.
- And check for domination between each pivot pair
- Only ask the oracle for pivot values
- Watch for new arrivals if they fall outside of a pivot pair
- Only ask the oracle for score on instances that fall outside the pair.
- Check them for domination against the non-dominated 2 pivot pairs
- Forget them if they are dominated
- Else, add them to that "important" set
- Every (say) 1000 instances,
- Forget everything except the non-dominated pivots and the non-dominated newbies.
- Rebuild the cluster tree
Friday, March 9, 2012
This article highlights a possible application for the research I am involved with. Very exciting!
Tuesday, March 6, 2012
Thesis Progress
Chapter 2 (literature review) is currently halfway done at 6 pages + 1. After a quick break to finish deliverables for my classes, I intend to finish the other half by Saturday morning.
The current state of the thesis draft can be found at http://unbox.org/stuff/var/jcraig/thesis/ .
The good news is that the more I read, the more ideas I have as to how things might be done differently. For example, a comparison of NSGA-II against a very similar algorithm, SPEA2, shows that NSGA-II performs better on lower dimensional problems, because it converges a little bit faster than SPEA2. However, SPEA2 does better with higher-dimensional problems, and it gets better distributions. The differences between the two algorithms are so minor that it is a simple matter to tinker with NSGA-II to determine whether it can have SPEA2's distribution while maintaining its speed.
On the local search front, the algorithm EPLS (Evolutionary Parallel Local Search) performs similarly to my modified NSGA-II, but they report performing well against other algorithms (not including NSGA-II, oddly enough). I can try using kNN clustering like they do and using a different breeding operator for the local search like their simplex crossover to see if that gets better results than our clunky FastMap + V-optimal recursive splits with binary uniform crossover.
The current state of the thesis draft can be found at http://unbox.org/stuff/var/jcraig/thesis/ .
The good news is that the more I read, the more ideas I have as to how things might be done differently. For example, a comparison of NSGA-II against a very similar algorithm, SPEA2, shows that NSGA-II performs better on lower dimensional problems, because it converges a little bit faster than SPEA2. However, SPEA2 does better with higher-dimensional problems, and it gets better distributions. The differences between the two algorithms are so minor that it is a simple matter to tinker with NSGA-II to determine whether it can have SPEA2's distribution while maintaining its speed.
On the local search front, the algorithm EPLS (Evolutionary Parallel Local Search) performs similarly to my modified NSGA-II, but they report performing well against other algorithms (not including NSGA-II, oddly enough). I can try using kNN clustering like they do and using a different breeding operator for the local search like their simplex crossover to see if that gets better results than our clunky FastMap + V-optimal recursive splits with binary uniform crossover.
Possibility of Effort Estimates without Software Size
The detailed results are:
- Only instance selection:
- Quick vs. 1NN: 2 losses out of 13 data sets
- Quick vs. CART: 4 losses out of 13 data sets
- Only feature selection:
- Quick vs. 1NN: 4 losses
- Quick vs. CART: 6 losses
- Both feature and instance selection:
- Quick vs. 1NN: 3 losses
- Quick vs. CART: 5 losses
Monday, March 5, 2012
Redesigning Games
The game I made earlier this year: AiMazed
- Random dungeons are built and your job is to pilot a car through the maze and find:
- - - > A key
- - - > An exit
- - - > Enough crystals to power the exit warp
- Meanwhile, there is also an AI computer agent doing the same thing
My (Re)Design Methodology, buffed up a bit:
---Pre-Production of a working version---
- 1. Design the Game
- 2. Guess the AR Vector for your game (AR_PROJECTED) based on your own experience
- - - > 2b. Or, look up an AR Vector from previous knowledge based on the game class/genre
- 3. List each feature in your game
- 4. Score each feature in your game for AR (AR_i)
- 5. Add weights if necessary to the above features
- 6. Average each feature (AR_AVG)
- 7. Compare AR_AVG and AR_PROJECTED
- 8. Add features based on comparison in (7)
--- Post Production of a working version ---
- 9. Discover disruptions to game play and propose fixes to them
- 10. Propose whatever other suggestions you deem appropriate
If the AR_AVG for some aspect is less than that aspect in AR_PROJECTED, then you need to add some features to bring the AR_AVG up to the projection.
Above is put to work to redesign and make AiMazed better.
- This will give us two versions of the game
- Need places (separate places) to post game and get ratings
- Hypothesis: V2 using my method gives a better rating
Subscribe to:
Posts (Atom)